RAID Configuration
RAID stands for Redundant Array of Independent Disks. RAID is a method of combining several hard drives into one unit. It offers fault tolerance and higher throughput levels than a single hard drive or group of independent hard drives. RAID levels 0,1, 10 and 5 are the most popular.
RAID Calculator
https://www.icc-usa.com/raid-calculator
Parity is a means of adding extra data, so that if one of the bits of data is deleted, it can be recreated from the parity. For example, suppose a binary halfword consists of the bits 1011. The total number of ‘1’s in the halfword is odd, so we make the parity bit a 1. The halfword then becomes 10111. Suppose the third bit is lost, the halfword is then 10?11. We know from the last bit that there should be an odd number of ‘1’s, the number of recognisable ‘1’s is even, so the missing but must be a ‘1’. This is a very simplistic explanation, in practice, disk parity is calculated on blocks of data using XOR hardware functions. The advantage of parity is that it is possible to recover data from errors. The disadvantage is that more storage space is required.
RAID0 is simply data striped over several disks. This gives a performance advantage, as it is possible to read parts of a file in parallel. However not only is there no data protection, it is actually less reliable than a single disk, as all the data is lost if a single disk in the array stripe fails.
RAID1 is data mirroring. Two copies of the data are held on two physical disks, and the data is always identical. RAID1 has a performance advantage, as reads can come from either disk, and is simple to implement. However, it is expensive, as twice as many disks are needed to store the data.
RAID2 is a theoretical entity. It stripes data at bit level across an array of disks, then writes check bytes to other disks in the array. The check bytes are calculated using a Hamming code. Theoretical performance is very high, but it would be so expensive to implement that no-one uses it.
RAID3 A block of data is striped over an array of disks, then parity data is written to a dedicated parity disk. Successful implementations usually require that all the disks have synchronised rotation. RAID3 is very effective for large sequential data, such as satellite imagery and video.
RAID4 data is written in blocks onto the data disks (i.e. not striped), then parity is generated and written to a dedicated parity disk
RAID5 data is written in blocks onto data disks, and parity is generated and rotated around the data disks. Good general performance, and reasonably cheap to implement. Used extensively for general data.
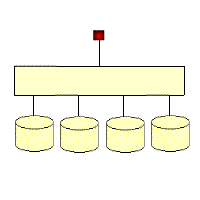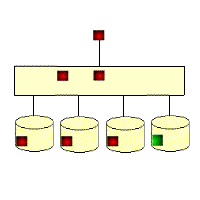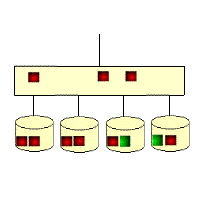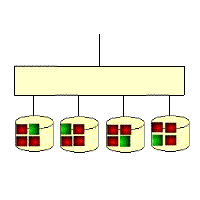
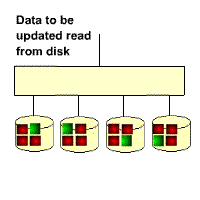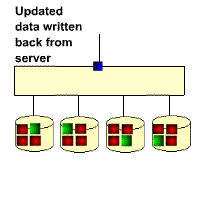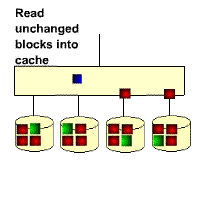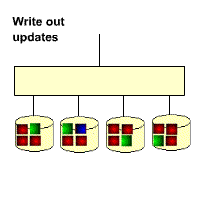
The gif below illustrates the RAID5 write overhead. If a block of data on a RAID5 disk is updated, then all the unchanged data blocks from the RAID stripe have to be read back from the disks, then new parity calculated before the new data block and new parity block can be written out. This means that a RAID5 write operation requires 4 IOs. The performance impact is usually masked by a large subsystem cache.
As Nat Makarevitch pointed out, more efficient RAID-5 implementations hang on to the original data and use that to generate the parity according to the formula new-parity = old-data XOR new-data XOR old-parity. If the old data block is retained in cache, and it often is, then this just requires one extra IO to fetch the old parity. Worst case it will require to read two extra data blocks, not four.
 RAID 5 often gets a bad press, due to potential data loss on hardware errors and poor performance on random writes. Some database manufactures will positively tell you to avoid RAID5. The truth is, it depends on the implementation. Avoid software implemented RAID5, it will not perform. RAID5 on smaller subsystems will not perform unless the subsystem has a large amount of cache. However, RAID5 is fine on enterprise class subsystems like the EMC DMX, the HDS USP or the IBM DDS devices. They all have large, gigabyte size caches and force all write IOs to be written to cache, thus guaranteeing performance and data integrity.
RAID 5 often gets a bad press, due to potential data loss on hardware errors and poor performance on random writes. Some database manufactures will positively tell you to avoid RAID5. The truth is, it depends on the implementation. Avoid software implemented RAID5, it will not perform. RAID5 on smaller subsystems will not perform unless the subsystem has a large amount of cache. However, RAID5 is fine on enterprise class subsystems like the EMC DMX, the HDS USP or the IBM DDS devices. They all have large, gigabyte size caches and force all write IOs to be written to cache, thus guaranteeing performance and data integrity.
Most manufactures will let you have some control over the RAID5 configuration now. You can select your block stripe size and the number of volumes in an array group.
A smaller stripe size is more efficient for a heavy random write workload, while a larger blocksize works better for sequential writes. A smaller number of disks in an array will perform better, but has a bigger parity bit overhead. Typical configurations are 3+1 (25% parity) and 7+1 (12.5% parity).
Leave a Reply
You must be logged in to post a comment.






